Просмотр текстовых файлов

Существует несколько утилит для просмотра текстовых файлов в консоли, такие как cat, less, и немного специфичные head, tail. Давай посмотрим на них подробнее:
less
Удобная утилита для просмотра текстовых файлов в консоли. Для базового использования достаточно набрать
less my_text_document
Документ отобразится на экране, его можно листать вверх/вниз/влево/вправо, искать слова.
Утилита less позаимствовала команды у своей предшедственницы, утилиты more, которая выполняла схожие функции, но по сравнению с less имеет некоторые недостатки. Также, часть команд less взяла из утилиты vi, которая является очень продвинутым текстовым редактором.
Для выхода из less достаточно нажать на клавишу q. Если не работает, скорее всего у вас включена русская раскладка клавиатуры.
В less поиск осуществляется от начала документа к концу при помощи символа / + искомая строка. То есть если вы хотите найти слово foo в начале документа, наберите /foo.
Также присутсвтует поиск с конца документа, при помощи символа ?. Аналогичным образом набираете ?foo.
Для перехода к следующему совпадению нажмите на ‘n’, к предыдущему - N
(т.е. shift + n).
пример поиска фразы
bar
Чтобы перейти в самое начало документа используйте клавишу g, в конец документа -
G.
cat
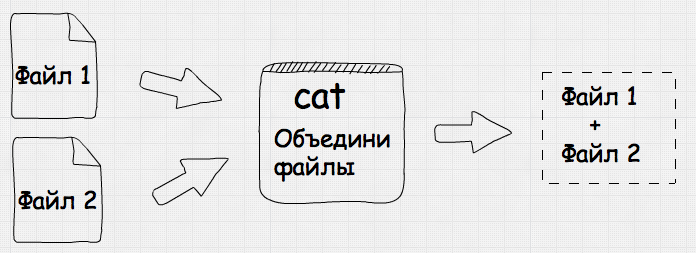
Название этой утилиты не имеет ничего общего с котами и кошками и является сокращением от concatenate (конкатенация). При помощи этой утилиты можно конкатенировать файлы. Воу воу, что же такое конкатенация? Давайте обратимся к википедии:
Конкатена́ция (лат. concatenatio «присоединение цепями; сцепле́ние») — операция склеивания объектов линейной структуры, обычно строк. Например, конкатенация слов «микро» и «мир» даст слово «микромир».
При конкатенации файлов текста из них будут просто объединяться, однако, как это поможет нам прочесть файл? Давайте глянем в документацию, а именно в man cat:

Утилита cat не только конкатенирует файлы, но и печатает их на консоль, чем собственно мы и воспользуемся. Если мы передадим всего один файл в эту утилиту, то она просто напечатает его на экране (и впрямь, объединять его ведь не с чем):
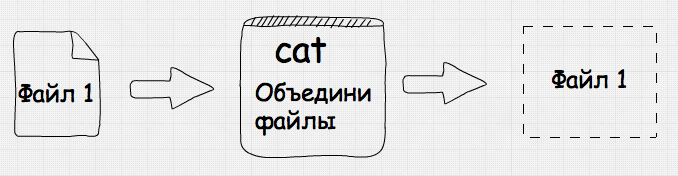

Давай попробуем объединить два файла и вывести их на экран:

head
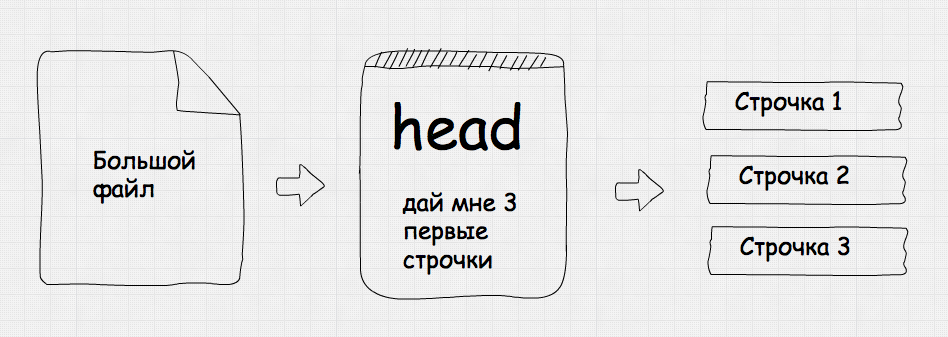
Эта утилита выводит несколько первых строк из файла. Просто и удобно. Зачем это нужно, скажете вы? Допустим, у нас есть файл, причем файл довольно объемный, мегабайт так на 50. При помощи cat его не просмотришь, он просто не влезет в консоль (да да, вывод в консоль ограничивается некоторым числом строк, число выставляется в настройках эмулятора терминала) и будет показан только его конец.
Настройка числа строк в iTerm 2. Есть опция неограниченного числа строк (unlimited srollback), но в нашем случае это не панацея

Давате попробуем head в деле. Для начала сделаем файл с несколькими строками:

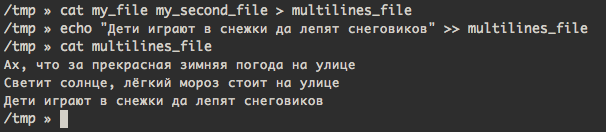
Вначале объединим два наших файла и вывод утилиты cat направим в новый файл. Затем добавим новую строку при помощи команды echo.
Проверим содержимое файла:
Затем глянем в man head:
Мини-раздел “читаем документацию в man”
Очень важно научиться читать документацию. Да, она на английском языке, поэтому вооружаемся словариками. Пройдемся по разделам и попробуем понять, что же из себя представляет утилита head:
NAME
Приведено название команды и что она в принципе делает. Вольный перевод:
head --отоборажает первые строки файла
SYNOPSIS
Синопсис содержит в себе информацию о том, как можно использовать команду. Синопсис утилиты head выглядит следующим образом:
head [-n count | -c bytes] [file ...]
Как это понимать? Для начала взглянем на то, что он разделён на блоки:
- head - имя утилиты
- [-n count | -c bytes] - флаги с параметрами
- [file ...] - основные параметры утилиты
Давайте попробуем разобраться что к чему. С первым блоком должно быть все понятно.
Второй блок заключен в квадратные скобки. Что это значит? Квадратные скобки означают то, что находиться в них является необязательным!. Мы можем вызвать команду без этого блока.
С квадратными скобками мы разобрались и можем их опустить. Теперь можно представить второй блока как -n count | -c bytes. Как было уже сказанно выше, этот блок содержит флаги. Флаги обычно начинаются со знака - и позволяют передать утилите дополнительные параметры. Здесь есть два флага:
-n count- устанавливаем количество выводимых строк (как мы помним,headвыводит несколько первых строк файла)-c bytes- устанавливает количество выводимых байт (например, мы хотим вывести первые 1024 байта, иногда полезно)
Как можно заметить, флаги разделяет символ вертикальной черты | . Данный символ принято читать как ИЛИ . Мы выводим несколько строк ИЛИ некоторое количество байт, но вместе эти параметры использовать нельзя.
Взглянем на поледний блок [file ..]. Внутри него можно передать файл или несколько файлов, из которых будут выведены первые строки. По квадратным скобкам становится ясно, что он тоже не обязателен к написанию. Но как же так, если мы не напишем из какого файла выводить строки, что же будет??? Читаем документацию дальше
Description
Тут уже идет нормальная, человекочитаемая документация на английском языке.
This filter displays are the first count lines or bytes for each of the specified files, or of the standart input if no files are specified - Этот фильтр отображает заданное число первых строк или байт из каждого указанного файла или использует стандартный поток ввода если файлы не заданы.
Как видно, head назвали фильтром. При помощи него можно фильтровать информацию в так называемых пайплайнах (pipe-line) или как их ещё называют конвеерах. Это отдельная глава, сейчас мы коснёмся её лишь вскользь. И так же мы поняли, что если мы не укажем третий блок с файлами, то утилита head будет брать информацию из stdin.
If count is omitted it defaults to 10. - Если число строк не указано, будет использованно значение по-умолчанию равное 10.
Ага, если мы пропускаем второй блок, и не указываем число строк или число байт, то по-умолчанию выводятся первые десять строк.
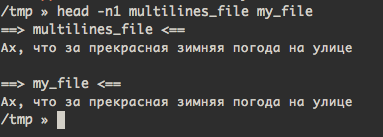
If more than a single file is specified, each file is preceded by a header consisting of the string ``==> XXX <=='' where ``XXX'' is the name of the file. - Если указанно более одного файла, каждый файл будет начинаться со строки вида ==> XXX <==, где XXX - имя файла. Ну, сделанно это явно для удобства.
EXIT STATUS
Exit Status - число, которое возвращает утилита по завершению своей работы. По этому числу можно определить, закончила ли программа работу корректно, или случилась какая-то ошибка.
The head utility exits 0 on success, and >0 if an error occurs. - Утилита head возвращает 0 в случае успешного завершения работы и число большее нуля в случае возникновения ошибок.
SEE ALSO
Схожие по функционалу утилиты. В данном случае приведена утилита tail
HISTORY История утилиты
Прочёв документацию можно начать пользоваться утилитой head:
- head -n 5 foo - читаем 5 первых строк из файла foo
- head -b 2048 foo - читаем 2048 байт из файла foo
- head foo - читаем 10 (по-умолчанию) строк из foo
- cat my_big_file | head -n 20 - это один из примеров использования конвеера. Не дай себя запутать, если вы читали про стандартные потоки, то знаете что тут символ прямой линии | связывает выходной поток предшествующей ему программы с входным потоком следующим за ним программы. В данном случае в начале мы читаем большой файл my_big_file при помощи утилиты cat и направляем выходной поток не в консоль для вывода текста, а соединяем его с входным потоком утилиты head (заметь, мы вызвали head без указания файла). В данном случае в head попадает текст из утилиты cat, head берёт из него 20 первых строк и выводит на экран
tail

Задание домой: разобраться в работе tail самостоятельно, утилита схожа с head